Understand how to approach designing queues in Node
A new scenario you might not have faced before: you have a long running task (like saving to a bunch of different databases, or processing video) that takes a while to process and it's currently causing your REST API response times to be way too slow for the end user.
After some research, you've realized adding a queue to your architecture would solve your problem.
The only problem is, working out how a queue actually works is confusing.
You knew how to build the REST API, that was within your realm of experience and knowledge. You've built API's before...
But a queue? You might feel like you're flying blind.
And if you're using Redis to implement your queue, you might be wondering how Redis even works as the underlying system for a queue...
But if you understood the design patterns involved and could leverage Redis to build a production-quality queue?
Armed with this knowledge, you could add an architectural pattern to your toolbelt beyond building basic REST API's.
Aside from making your application responses faster for whatever is calling your API, being able to work at the architecture-level is often what makes a developer a senior developer.
In this post we'll be going over the architecture for how a queue works (using the reliable queue pattern) so you can achieve exactly these things.
What is the reliable queue pattern?
First, let's describe a "normal" queue. A normal queue is one where a producer pushes a message/work item to the queue, and a consumer pops it off the queue and does the work.
This works great, but it is not reliable - meaning messages can be lost. Some examples of this would be if there is a network blip when the consumer is pulling a message from the queue, or if the consumer crashes after it's popped the message from the queue, but has yet to process it / do the work.
This is where the reliable queue comes in. With this pattern, the consumer pops from the queue and immediately pushes it to a "processing" queue. So there will always be two queues in this pattern. Think of it like a back up.
When the consumer is done processing the message/working on the item, it will just remove it from the processing queue.
What this looks like in diagrams
The above description might not click until you've seen it described using diagrams. Let's go over that now.
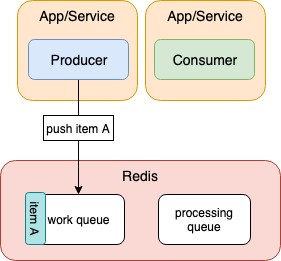
First, the producer pushes a work item to the work queue. The work queue will contain the items to be processed.
Here, we're using a FIFO (first-in-first-out) queue, so the items will be popped off the queue in order.
Note that a "work item" is metadata about the job to be processed. Think of it as "just enough information for the consumer to take it and complete its job".
Also note that, as shown in the diagram, producers and consumers are typically separate services. They can exist in the same service but then you lose some of the benefits of reliability.
And there can be multiple producers and multiple consumers, you're not limited to just one producer and one consumer.
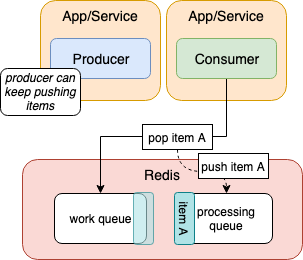
It's important to remember that queues are asynchronous, that's kind of the whole point. But I'm calling this out to note that the producer(s) can keep pushing items to the work queue while the consumer is processing items. (The queue can keep being filled up).
While the producer is doing it's thing, the consumer will pop the next item off the work queue and push it into the processing queue.
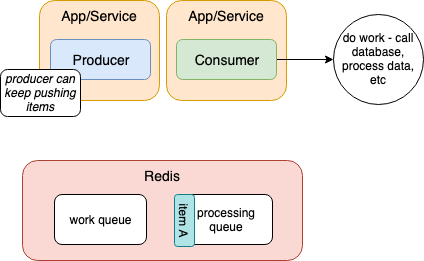
From there, the consumer will process the work item.
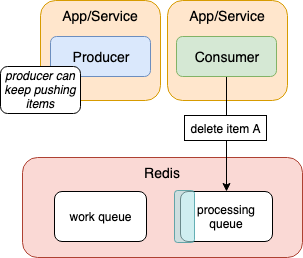
After the item has been successfully processed, only then will it be removed from the processing queue. We'll get into this when we look at the code, but it will use the Redis command `lrem` to remove it. This command doesn't pop the item off the queue but removes it entirely.
What this looks like in code
Now that you've got an idea of how a queue system works from an architecture perspective, let's go over what this looks like in code.
In this example, we'll be pushing items to a work queue and then consuming them and saving them to a database.
If you want the full code now, along with setup instructions, sign up below:
Subscribe for the code!
No spam ever. Unsubscribe any time.
Producer code
Let's look at the function we'll use to push items into the queue:
const pushToQueue = async (queueName, data) => {
try {
await lpush(queueName, data) // lpush comes from the Redis module
} catch(e) {
console.error(`Error pushing to queue: ${e}`)
}
}
The pushToQueue function takes as arguments the queue name to push the items to, and the actual data to push to the queue.
Note: we use Redis lists to act as queues. There is no official queue data type in Redis, but lists are really just queues.
lpush is a Redis command to push items to the left side of the queue. Later on we'll pop them off the right side of the queue, so it acts as a FIFO queue.
Then we use this function to push items into the queue:
for (let i = 1; i <= 20; i++) {
await pushToQueue(WORK_QUEUE, JSON.stringify({
itemNum: i,
isbn: 'default',
timestamp: Date.now()
}))
}
For demo purposes, we're just using a for loop here to push the items, but in your application you'll just be calling pushToQueue from whatever function is producing the work to be done later.
We JSON.stringify() it so that it gets stored as a string in the Redis queue, as we can't store a JavaScript object. We'll JSON.parse() it later when we actually fetch the item.
Consumer code
Now that we've gone over the producer code, let's look at the consumer code.
The consumer has a few main duties:
- Monitor the work queue for new work
- Get the work data from the queue
- Do the work
We'll cover duties 2 and 3 first, then come back to how to monitor the work queue
Getting and doing the work
Our functions for getting and doing the work are as follows:
const getWork = async (workQueue, processingQueue) => {
try {
// this removes from work queue
return await rpoplpush(workQueue, processingQueue)
} catch(e) {
throw new Error(e)
}
}
const doWork = async (workItem, processingQueue) => {
const {itemNum, isbn} = JSON.parse(workItem)
try {
await insert('books', itemNum, isbn)
await lrem(processingQueue, 1, workItem)
} catch(e) {
throw new Error(e)
}
}
When we get the work item from the work queue, we use Redis' rpoplpush command to pop the item from the work queue and immediately push it to the processing queue for tracking. The getWork function does this and also returns the work item data itself. That way when it comes time to do the work, we already have the data in hand.
The doWork function takes that work item data, parses it back into an object, and destructures the data we need.
From here, we insert the data for that work item into the database and then remove the item from the processing queue. The work is complete and our tracking of that work is complete!
Note that we could make the doWork function more generic, taking the actual function that specifies the work to be done as an argument. This is a minor improvement you can make if you choose.
Removing an item vs. popping the item
`lrem`, what we use to remove the item in the doWork function, is a Redis command to remove an item from a queue rather than popping it from the queue.
At this point, we've already successfully done the work / processed the data, and so popping the item from the processing queue would remove it, but also give us the data back. That data is now useless though, so we can save that step and just remove the item entirely.
Monitoring the work queue
Now, for monitoring the work queue for work to be done, there are a few steps involved with that:
- Check if work queue still has items to process
- If there are items in the work queue, get the work and do the work
Let's look at the code:
const checkQueueHasItems = async (queueName) => {
return !!(await lrange(queueName, 0, -1)).length
}
Here we use Redis' lrange command to check the items still in the queue. This command returns an array, so we check if there is length to that array. If it's empty we return false. If it still has items, we return true.
const run = (async() => {
let workQueueHasItems = await checkQueueHasItems(WORK_QUEUE)
while (workQueueHasItems) {
// not necessary, just to be able to see the console logging output more easily
await sleep(500)
let workItem
try {
workItem = await getWork(WORK_QUEUE, PROCESSING_QUEUE)
} catch(e) {
console.error(`Error getting work item from ${PROCESSING_QUEUE} queue: ${e}`)
}
try {
await doWork(workItem, PROCESSING_QUEUE)
console.log(`completed work item: ${workItem}`)
} catch(e) {
console.error(`Error doing work from ${PROCESSING_QUEUE} queue: ${e}`)
}
workQueueHasItems = await checkQueueHasItems(WORK_QUEUE)
}
process.exit()
})()
Finally, we use a while loop to check if the work queue still has items, and then we call the getWork and doWork functions we covered above.
In a production application, you'll want to keep polling for work items (maybe on a setInterval()), but for demo purposes here we just use a while loop. When all the items have been processed from the work queue, the process will exit.
To give you a more visual sense of how this runs:

One more thing, monitoring the processing queue for failures
Remember that the point of the reliable queue pattern is to be, well, reliable. What if we end up encountering one of the failures described at the beginning of this post? I.e. - that consumer crashes after fetching the work or fails during processing of the work?
Fortunately, with our design here, those items will remain in the processing queue as a backup.
But we need to monitor that processing queue in case some items get stuck there for a while. If they've been there for a while, that means we encountered a consumer failure earlier and need to "re-queue" those items.
Let's go over that code:
const peek = async (queueName) => {
// returns first item data without popping it
const item = await lrange(queueName, 0, 0)
if (item.length) {
// lrange returns array of one item, so we need to return the item, not the array
const itemFromArray = item[0]
return JSON.parse(itemFromArray)
}
return null
}
peek allows use to see the item at the front of the queue without popping it/removing it from the queue. This is needed so that we can check the timestamp for that item and determine how long it has been there! But obviously we don't want to remove it just yet, we just want to check how long it's been there in case we need to re-queue it.
Because we're polling this queue, the idea is that it's ok to only check the first item to see if it's stale. Since it's the "oldest" one, it would be the first to become stale. And if it is stale, after we requeue it, we'll check the next oldest item. And clear out the queue that way.
const requeue = async (workQueue, processingQueue, workItem) => {
const stringifiedWorkItem = JSON.stringify(workItem)
try {
await client
.multi()
.lpush(workQueue, stringifiedWorkItem)
.lrem(processingQueue, 1, stringifiedWorkItem)
.exec()
} catch(e) {
throw new Error(e)
}
}
requeue will push the item back to the work queue, so we can start the process over again. This is only in the case that we hit a stale item in the processing queue (i.e. - the consumer crashed, the database insert failed, etc.).
Note that this uses Redis' multi command, which allows for atomic operations. This operation needs to be atomic because we need to push to the work queue and remove from the processing queue without any of the other Redis clients that may be connected (i.e. - any other consumers) interfering.
Else, we might end up with two consumers interrupting the process, trying to push the item again to the work queue when it's already been pushed, but before it's been removed from the processing queue.
const checkStales = async (workQueue, processingQueue, timeout) => {
const processingQueueItem = await peek(processingQueue)
if (!processingQueueItem || !processingQueueItem.timestamp) return null
const timeSpentInQueue = Date.now() - processingQueueItem.timestamp
if (timeSpentInQueue > timeout) {
// if it fails, next consumer will try again, no try/catch needed
return await requeue(workQueue, processingQueue, processingQueueItem)
}
return null
}
The checkStales function checks to see if any items in the process queue have been there for too long. It compares the timestamp from the item at the front of the queue against a timeout we specify as an argument. If it's been there longer than the timeout, we re-queue it.
Our modified monitoring/run function
Then we just need to modify the monitoring/run function to actually check for stale items in the polling / while loop. It's just a matter of calling the checkStales function, but I'll show the entire function here:
const run = (async() => {
let workQueueHasItems = await checkQueueHasItems(WORK_QUEUE)
while (workQueueHasItems) {
// first, check stale items in processing queue
await checkStales(WORK_QUEUE, PROCESSING_QUEUE, 120000) // 2 minute stale time
// not necessary, just to be able to see the console logging output more easily
await sleep(500)
let workItem
try {
workItem = await getWork(WORK_QUEUE, PROCESSING_QUEUE)
} catch(e) {
console.error(`Error getting work item from ${PROCESSING_QUEUE} queue: ${e}`)
}
try {
await doWork(workItem, PROCESSING_QUEUE)
console.log(`completed work item: ${workItem}`)
} catch(e) {
console.error(`Error doing work from ${PROCESSING_QUEUE} queue: ${e}`)
}
workQueueHasItems = await checkQueueHasItems(WORK_QUEUE)
}
process.exit()
})()
Wrapping up
Next time you're faced with heavy/longer operations you need to offload for later processing, use this as a starting point for implementing your queue. You'll not only have a better starting point, you'll be able to understand one more piece of the architecture.
Just a note - queue design can vary based on the requirements of your application. Distributed, failover, might require you to design your queue a bit differently, but this will get you off the ground and running.
And for the demo code shown here, it requires a bit of setup. You need Postgres and Redis installed and running, scripts to empty the queues when you're playing around with the code (they might get messy or filled up with a lot of items from prior test runs), and instructions for all this.
Want the full code repo with those scripts and instructions? Subscribe below! You'll also get any updates to the code as well as new semi-weekly posts delivered directly to your inbox as soon as I hit "publish".
Subscribe for the code!
No spam ever. Unsubscribe any time.