Why should your Node.js application not handle log routing?
It is not the responsibility of the application to route logs.
12 Factor says that logs should go to STDOUT. WAT? WHY?
I just configured my whole application code to write logs to custom log files. What's wrong with that?
Logging is one of those things that can sometimes be a black box for developers. Maybe you have a dedicated DevOps person who takes care of logging infrastructure for you, or maybe it's your first time working on this side of things.
It can be one of those things you leave until last to take care of while you're too busy working on writing code. Many do, making the "best practices" around logging seem like something you can just ignore, if you even understand them in the first place...
We're going to take a look at deciphering the reasons behind the best practices of decoupling your logging from your application, and where you should actually log to. And for purposes of this post, "log routing" - as referenced in the title - refers to picking up and pushing the logs to an intended logging target that is not your application or application process.
Best practices illuminated
You may have heard of the 12 Factor App before, which is considered the canonical "best practices" document around creating modern, scalable applications.
From the "12 Factor App best practices regarding logs":
A twelve-factor app never concerns itself with routing or storage of its output stream. It should not attempt to write to or manage logfiles. Instead, each running process writes its event stream, unbuffered, to stdout.... In staging or production deploys, each process’ stream will be captured by the execution environment, collated together with all other streams from the app, and routed to one or more final destinations for viewing and long-term archival. These archival destinations are not visible to or configurable by the app, and instead are completely managed by the execution environment.
That's a lot to decipher, so let's break it down.
A twelve-factor app never concerns itself with routing or storage of its output stream.
The first major reason why you don't want your application code to handle routing of logs itself is due to separation of concerns. We often think of this separation in terms of pieces of code between services and between services themselves, but this applies to the more "infrastructural" components as well. Your application code should not handle something that should be handled by infrastructure.
This code below is an example of highly coupled application code.
const { createLogger, transports, winston } = require('winston');
const winston-mongodb = require('winston-mongodb');
// log to two different files
const logger = createLogger({
transports: [
new transports.File({ filename: 'combined.log' }),
],
exceptionHandlers: [
new transports.File({ filename: 'exceptions.log' })
]
});
// log to MongoDB
winston.add(winston.transports.MongoDB, options);
Let's leave the deployment environment concerns out of it for a moment, which we'll look at later, and instead focus on the application itself.
Just by having the application handle logging, it now has taken on another "concern" under its wing. By defining what the logging outputs are, the application now handles both application/business logic AND logging logic.
What if you need to change your logging location later? That's another code change and deployment (and more if you have a strenuous QA/change control/deployment process). And what if you get a logfile name wrong? Again, another code change and deployment.
This is not to say your application should take an extreme stance towards logging and avoid log statements as well - you do have to log something, after all - but it is to say that the log routing adds another layer which does not belong in the application if you want to decouple components of your code and keep your application code clean.
Next,
It should not attempt to write to or manage logfiles. Instead, each running process writes its event stream, unbuffered, to stdout.
(Side note: although it specifically mentions stdout, I take it to mean stdout and stderr, and cursory Google searches seem to confirm this.)
I already discussed above why logging to outputs like files and databases is not a good practice from a separation of concerns perspective. But this is where the environment concerns start to be addressed.
In Node.js applications, you are still logging to something and that is the console (using usually either console.log() or console.error()).
The console, under the hood, prints to stdout for console.log() and stderr for console.error(), so simply by using this module, it looks like we pass this test.
And this test exists for a reason: if you've worked with physical or even virtual (but not container/cloud) servers before, you might have had only a handful of them, or at least a size that was manageable enough to manually configure the logfiles, their locations, and any other setup.
Now imagine your application has had some big success and is onboarding hundreds of new users everyday. Your team has begun migrating to a cloud-based environment, and you have to plan for your application scaling on-demand from 1 instances to 50. You won't know where those instances are running, so you can't control where exactly the logfiles get written to.
It's more useful to have stream | target, as opposed to target -> (your routing solution) -> target. Streams give us the ability to pipe anywhere, composing together powerful pipelines. If you've ever used Linux/Unix, you can build up powerful operations simply by piping streams together, like searching for text within a file: cat example.txt | grep sometext. stdout/stderr gives you this power. For example, you could pipe from stdout to a logfile if you wanted to.
Furthermore, cloud applications are ephemeral. They can spin up, spin down, crash, etc. which means the logs are ephemeral too.
So while we started out looking at why an application should not handle routing logs to files/databases/other persistent storage targets, this brings up the question: is it ok to log to those targets at all?
Next,
In staging or production deploys, each process’ stream will be captured by the execution environment, collated together with all other streams from the app, and routed to one or more final destinations for viewing and long-term archival. These archival destinations are not visible to or configurable by the app, and instead are completely managed by the execution environment.
This helps answer that question. It's OK to route the logs to persistent storage (and you, in fact, absolutely should) if the execution environment does this routing from the stdout/stderr logs.
This also re-affirms the separation of concerns covered earlier. We can't be sure where a logfile might end up. And if a container crashes - and logfiles weren't being picked up by a log router in the first place - you're screwed. Good luck debugging the reason your application crashed in the first place.
Cool, but then how do you manage logs in production? Is there a tool that picks up whatever is sent to stdout/stderr?
This is actually where the log routing piece comes in, the whole thing this post has attempted to dissuade you from handling from within your application code.
For simplicity's sake, assume you're using Docker for your containers as part of your cloud environment. The Docker daemon that runs on your Docker host - not your container - will by default pick up the logs from stdout/stderr from your container(s).
You configure the Docker daemon to use a logging driver, which does the actual log routing work of picking them up and routing them to a given storage target, like so:
In the daemon.json file,
{
"log-driver": "splunk", // just using Splunk as an example, it could be another storage type
"log-opts": {
"splunk-token": "",
"splunk-url": "",
// ...
}
}
You can view a list of logging drivers - which, again, do the work of picking up the logs and routing them - supported by Docker here. The list includes Greylog, Splunk, syslog, and other log aggregators you might be familiar with.
Routing the logs somewhere is important so that, in case your application crashes, boots up with scaling up, shuts down with scaling down, you have a persistent storage location from which to view them.
But it's important that this is done at the infrastructural level, for the reason discussed above.
A complete logging picture based on what's been discussed here would look like:
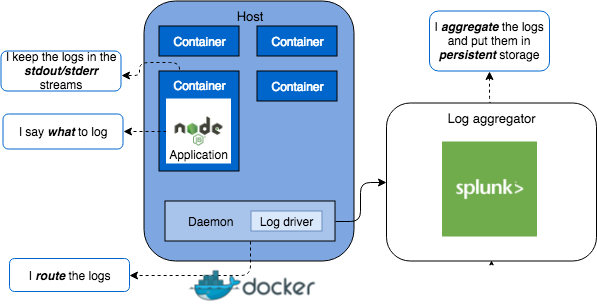
Wrapping up
To summarize the reasons you don't want to handle routing from your application and, by extension, to something other than stdout/stderr:
- keeping the log routing responsibility out of your application code:
- keeps the code cleaner
- makes log routing locations easier to change without deployments
- scaling applications/containers means it's harder to have control over logfiles
- scaling applications also means they're more ephemeral, meaning logfiles might not be there depending on the state of the container
- writing to, say a file or database, over
stdout/stderrties you down to those log targets, takes away your flexibility to pipe the output ofstdout/stderrto whatever targets you want, and change this on the fly
To address one last question you might be having: what if you're not using a cloud environment or containers?
My thoughts on this are as follows. The approach I've laid out here is still useful, because:
- you may one day move from physical or virtual servers to a cloud / container approach, making the migration path much easier on yourself or the team that will be doing the work
- you still keep that separation of concerns
- you can always just pipe the
stdoutto a log file or other persistent storage target and get the same advantages as a Docker daemon would provide
As you are working on implementing logging or reviewing your current logging code - if you are deciding between using a logging framework versus console.log() and console.error(), I wrote a post on that that can help you make the decision here. Just make sure keep this post here in mind and write to stdout/stderr from the logging framework unless you absolutely have reason to write to something else.
Lastly, I'm trying to make logging, testing, and other things in JavaScript easier by sending out tutorials, cheatsheets, and links to other developers' great content. Sign up below to join my newsletter if you found this post helpful!
Want to continue getting a better grasp on JavaScript and Node.js?
No spam ever. Unsubscribe any time.